In 2017, at midnight of new years eve, Cloudflare's DNS had an outage. The root cause of the crash was intriguing. An API that explicitly panics on negative input was unknowingly given a negative integer. It was the difference between a higher and a lower timestamp. Assuming that substracting a lower timestamp from a higher one will yield a positive number sounds reasonable. The only problem is that it is wrong. It is not a valid assumption because sometimes time moves backward in computers.
In this post, we will look at the problem of time measurement and clock synchronization. We will understand why keeping clocks in sync is the paramount issue in distributed systems. We will also look at the challenges of synchronizing the clocks across the network. We will briefly cover the different types of clocks and standards for measuring time and their inconsistencies.
Finally, we will end by taking a look at a couple of widely deployed clock synchronization protocols. How they tackle the clock synchronization problem and the different trade-offs that they make.
 |
|---|
Timekeeping
Before we look at how computers tell time, we will briefly examine how time is measured. In general, there are two broad types of clocks: astronomical clocks and atomic clocks.
The stability of a clock means how consistently it measures a unit of time.
Astronomical clocks are instrumental in applications related to navigation and astronomy because they match the earth's rotation. However, they are less stable. Atomic clocks are more stable but don't precisely match the earth's rotation.
More stable atomic clocks tend to be expensive, bulky, and hard to maintain. The usual wall clocks and computers that use quartz crystal oscillations are more prone to drifting. Environmental factors such as room temperature affect how fast quartz crystal oscillates. Quartz clocks can easily drift by 50 microseconds per second (50ppm).
 |
|---|
| NIST's ultra-stable ytterbium lattice atomic clock. Credit: Burrus/NIST |
Unix Time
Generally, computers keep time using the Unix time standard. It is defined as the number of seconds elapsed since the Unix epoch. The Unix epoch is 00:00:00 UTC on 1 January 1970. According to Unix time, each day contains 86400 seconds. The UTC standard is based on atomic clock reading, but it also periodically adjusts itself to sync with the earth's rotational period.
As measured in UTC, a day could be longer than 84600 seconds. The speed of the earth's rotation slows down gradually over time. Hence an astronomical day can have more than 86400 seconds when measured from an atomic clock.
To compensate for this drift, UTC has a standard practice. It occasionally adds a leap second to UTC time at midnight. The leap second was introduced in 1972. Earth's rotation speed also varies in response to climatic and geological events. That is why UTC leap seconds are irregularly spaced and unpredictable.
When the leap second is added, the UTC time goes from 23:59:59 to 23:59:60 and then finally to 00:00:00. After accounting for a leap second, a UTC day can be 84600 or 84601 seconds long. Another problem is that there is no way to represent the 60th second that UTC introduces in the Unix time. The Unix time simply repeats the last second to work around this limitation. The Unix time goes from 23:59:59 to 23:59:59 and finally to 00:00:00 to account for a leap second.
An alternative to adding leap second is to smear it. This technique recommends slowing down the clock for a longer duration instead of adding a second at one moment, such as midnight. For example, imagine that a leap second is announced for December 2022. In this case, we will slow down the clock at 2022-12-31 12:00:00 UTC and through 2023-01-01 12:00:00 UTC. One advantage of smearing the leap second over a long duration is that it keeps the frequency change small. The change for the smear is about 11.6 ppm. This is within the manufacturing and thermal errors of most machines' quartz oscillators.
Unix timestamp is essentially a number such as 1664955216. It is amenable to computers because we can represent it as an unsigned integer. However, it is not easily readable by humans.
Another common alternative to Unix time is ISO 8601. It was first proposed in 1988 and has been updated several times. It incorporates the elements of the 24-hour clock, a calendar, and a way of describing the timezone offset. For the notation, ISO 8601 uses Arabic numerals and specifically chosen characters such as "T, W, Z, -, and ": ."Such affordances make this representation more human-friendly. The purpose of ISO 8601 is to provide a straightforward method of representing calendar dates and times for global communication. We can convert between ISO 8601 and Unix time using the Georgian calendar.
Clock synchronization
Most computers don't have access to expensive atomic clocks. Instead, they rely on their hardware clocks. These clocks generally use humble tools like a quartz crystal for timekeeping. The operating system implements a system clock using the hardware clock. The software clock is set by the hardware when the system boots. The kernel delivers interrupts at dynamic intervals. It keeps the system clock updated.
Clock synchronization is an even more challenging problem for distributed systems. A distributed system is a set of computers that communicates by passing messages to each other and do not have access to a central clock. The individual nodes must obtain some common notion of time. No node will agree on the current time if the local clocks drift freely.
The purpose of designing distributed systems is often to coordinate real-time activities such as running factories, hospitals, and aircraft, recording inventory in databases, maintaining balances in bank accounts, etc. If the system's clock is not in sync with the real time, none of these systems can function.
Network Time Protocol
NTP or Network Time Protocol is a clock synchronization mechanism. It uses precise GPS receivers and atomic clocks to minimize drift. At this point, NTP is a widely adopted protocol. Most operating system ships with a pre-installed NTP daemon. The computer must connect to a centrally maintained NTP server such as time.apple.com to use it. As per the pre-defined configuration, the NTP daemon polls the time servers regularly to keep their clocks in sync with the network time.
 |
|---|
| NTP server setting in MacOS |
NTP is a UDP-based protocol. It works by relaying timestamps between different time servers across the globe over a packet-switched network like the internet. NTP organizes time servers in layers. Layer 0 only has the devices that keep the most accurate time, such as expensive atomic clocks and GPS receivers. The servers in layer 1 use layer 0 devices to sync their clocks. The servers in layer 2 use the servers in layer 1, and this goes on. NTP's goal is to reduce the clocks skew as much as possible1. However, even NTP-enabled servers can skew 100-200 milliseconds in UTC time.
NTP requires a reliable underlying network to function correctly. If the nodes don't have access to sufficient upstream or downstream bandwidth, the clocks might be off. To work around random network delays, NTP clients usually query multiple servers and poll one server multiple times before resetting their clock.
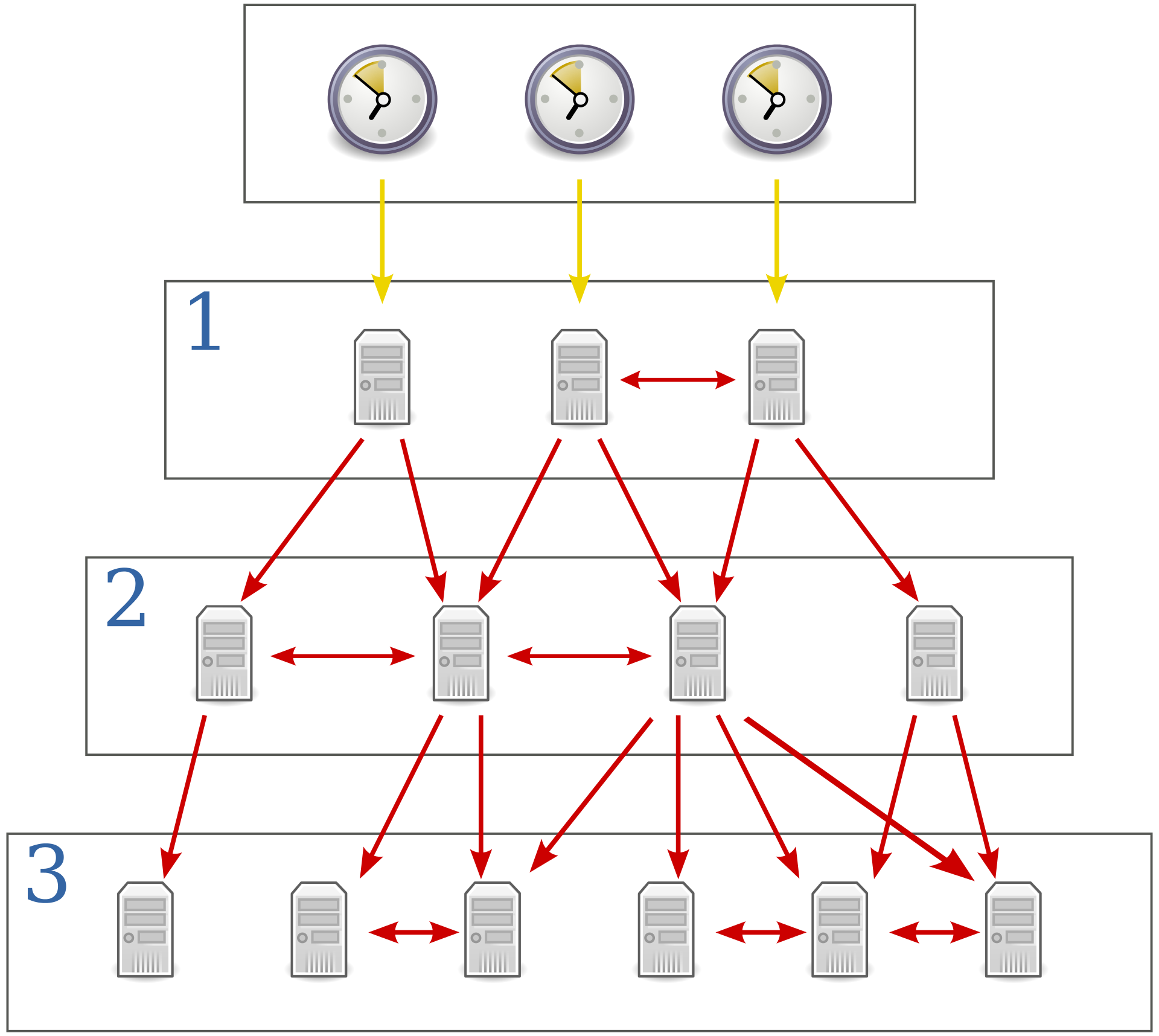 |
|---|
| NTP server architecture |
Notice that there is no way to measure the round-trip latency without having access to a global clock. It means that NTP needs to make a reasonable assumption about the network. It assumes that upstream and downstream network latency is the same2.
After an NTP client receives the network time, it calculates the skew locally. If the local clock is off by too much, then the client patches its current time. If the difference is insignificant, then the client adjusts the local clock rate to ensure that the local clock can catch up with the network time.
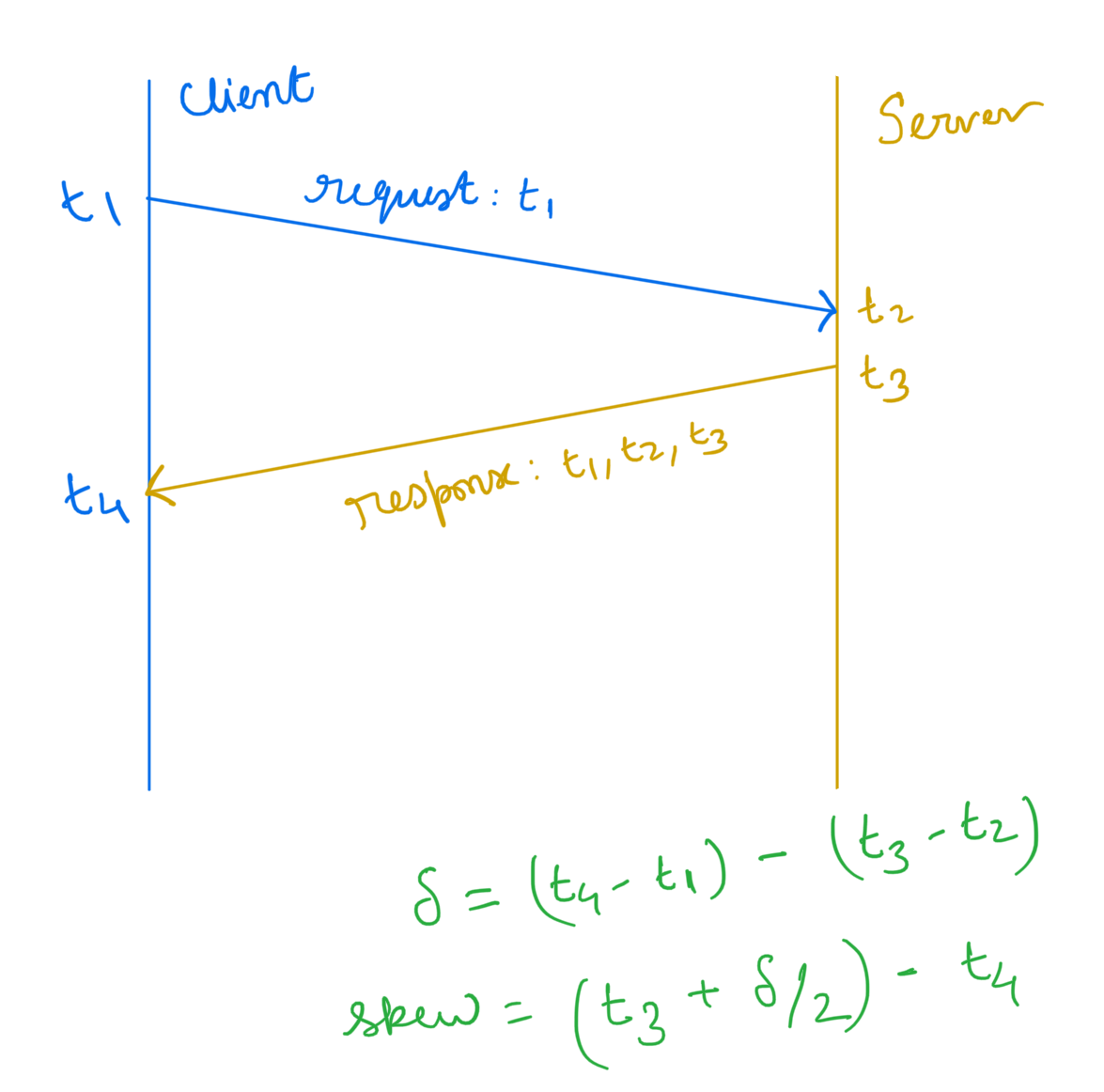 |
|---|
| NTP clock skew calculation |
Here is another problem. The NTP client can jump to a lower timestamp if the local clock is significantly ahead of the network time. It means that we cannot assume that the timestamps issued in our system are monotonic.
Operating systems generally give access to a wall clock and a monotonic clock. The wall clock can tell the "time of the day" according to the Unix time, but it may jump. The "monotonic clock" doesn't jump but cannot tell the current time. The monotonic clock returns time passed since an arbitrary point in the past, such as when the machine booted. To calculate the absolute time difference between two instances in a process, use the monotonic clock. The difference between two monotonic clock timestamps on the same device will never be negative3. In summary, the wall clock is for telling time, and the monotonic clock is for measuring time.
Programming languages offer different APIs for monotonic and non-monotonic clocks. For example, in the JVM, the timestamps given by system.currentTimeMillis is not monotonic.
This takes us back to the Cloudflare outage. Before Go version 1.9, the time.Now() function didn't return a monotonic timestamp. That is why, during a leap second, when Unix time froze for one second, the difference between the two timestamps that were only a few milliseconds apart produced a negative value crashing the application4.
 |
|---|
| Cloudflare DNS outage 2017: root cause |
Besides getting access to both astronomical and atomic time, there is another reason to have two different time sources. It makes the system robust. The GPS receivers may have an issue with their antenna, radio interference may block the signal, etc. On the other hand, atomic clocks in the data center may fail in ways uncorrelated to atomic clocks in the GPS satellites and other atomic clocks in different data centers. For example, clocks can significantly drift over long periods due to frequency error.
NTP works well in practice, but it is not perfect. It has its own set of problems. As we saw, NTP can make the clock jump forward and backward. It makes timestamps non-monotonic. Another issue with the NTP protocol is that it is centralized. The "network time" depends on the clocks at the top layer. It makes those clocks in layer 0 a central point of failure. Also, NTP needs a reliable network to function. It cannot reduce the clock drift at a node if it loses the network connection. It may also happen that the NTP client on the node crashes or a firewall accidentally blocks NTP traffic. In such cases, NTP will not work. The system will again suffer from clock skew.
 |
|---|
| @sadserver on twitter |
TrueTime
Google's TrueTime provides an order of magnitude improvement in clock synchronization compared to NTP. Similar to NTP, TrueTime uses the same time sources. That is a combination of atomic clocks and GPS clocks. However, organized in a different architecture.
TrueTime is built using expensive atomic clocks, GPS receivers, low latency data center connections, and extensive network engineering.
TrueTime timestamps are different. Instead of representing an instance, it represents an interval. This interval is a timestamp with an estimated error margin of calculated real-world time. There is a guarantee that the "actual" time must lie within the given interval.
 |
|---|
| TrueTime Timestamp |
There are two sources of error or uncertainty in the network clock. First, it could be that a particular node knows its clock is drifting and adjusts for the drift as an error. The second is the unpredictable network latency. Notice that sophisticated engineering efforts can reduce the latter to a certain extent.
Google ensures that the network latency is minimized by running TureTime entirely on their private Wide Area Network. That is, it does not rely on other 3rd party internet infrastructure for routing packets because it could be flaky.
Google has atomic clocks and GPS receivers in each data center. To synchronize the clocks on every server within the data center TrueTime classify the servers into two categories. The first type of server has access to high-end timekeeping devices. The other servers do not have direct access to these clocks. They use their own hardware clocks. However, they regularly synchronize their local clocks with the time servers within the same or nearby data centers.
The longer the servers don't check in with the time servers, the more uncertain the network time becomes. As soon as the nodes synchronize their clocks with the time server, the uncertainty in TrueTime goes down.
Google has managed to keep the uncertainty window low by ensuring non-timekeeping nodes sync with the timekeeping nodes every 30 seconds. The worst-case clock skew in NTP is about 100s of milliseconds, whereas TrueTime promises an uncertainty interval of a maximum of 7ms under normal network conditions.
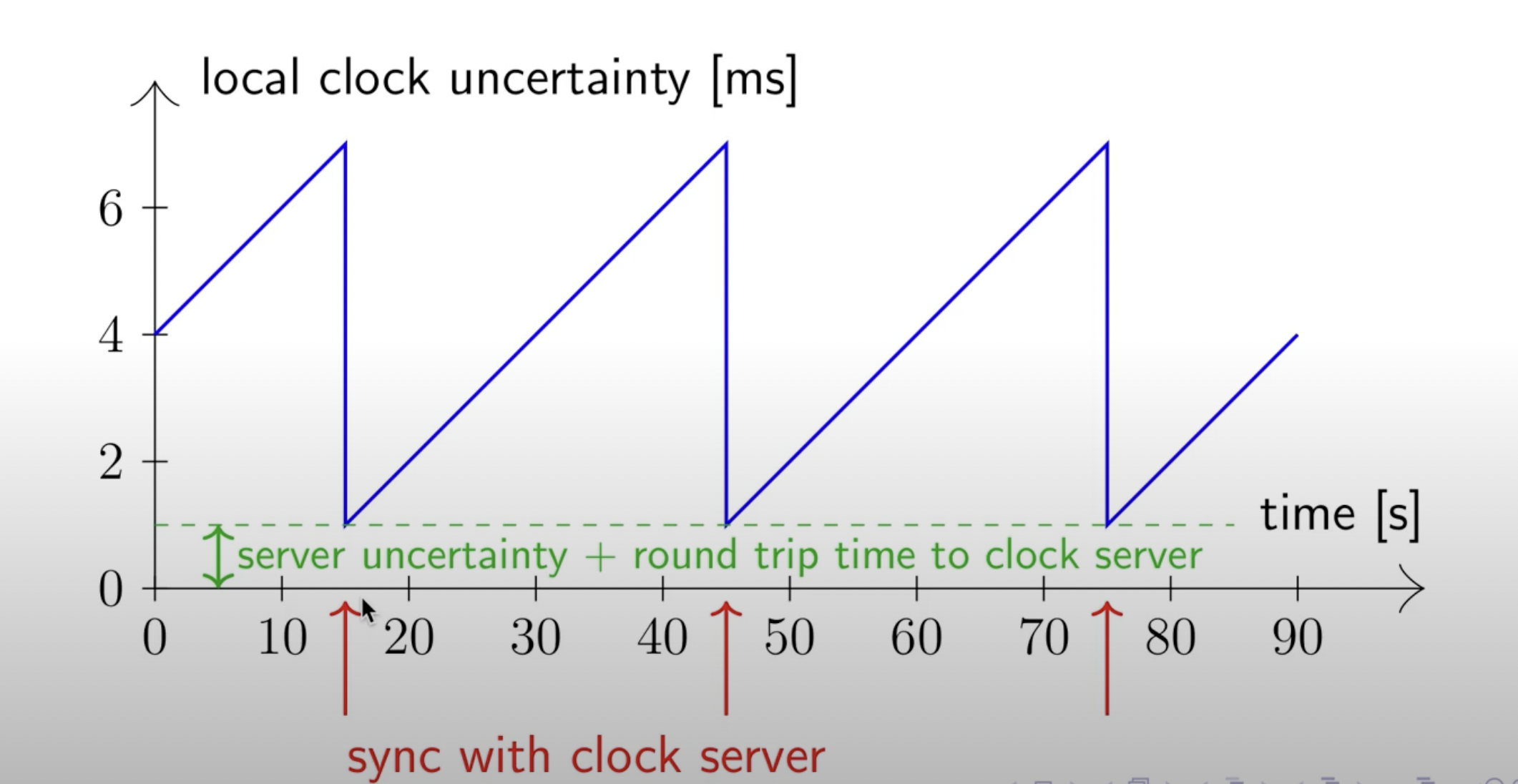 |
|---|
| Source: Martin Kleppmann's Distributed Systems Lecture Series |
It is worth noting that TrueTime doesn't guarantee the perfect globally synchronized clock. However, timestamps with uncertainty intervals can be as good.
Take the example of Google Spanner. It is a highly distributed ACID-compliant database. The Spanner database was the first substantial use case for TrueTime. Using TrueTime timestamps, Spanner can provide transaction isolation (I in "ACID") in the following way.
If two timestamps do not overlap, Spanner can be sure that the time on one timestamp is, in fact, earlier than the time on the other timestamp across all nodes in the network. However, if they overlap, Spanner pauses for the entire uncertainty interval. Recall that the maximum uncertainty window is only 7ms. Due to the small uncertainty interval, the database can simply wait before committing a new transaction without considerable performance degradation. It ensures that every node in the Spanner network has observed the first transaction before the second without ambiguity.
A final note about TrueTime is it can suffer from partitions too. Network partitions are not uncommon. During such an event, TrueTime's uncertainty interval increases. It leads to degraded performance in the systems such as Spanner that rely on TrueTime for clock synchronization. However, these systems can still function correctly with a low throughput until the partition heals5.
Conclusion
Computers need access to real physical time for various purposes. Operating systems need to know how long a process has been active for context switching. Databases need to attach a timestamp to the transactions for concurrency control. Applications need access to the current time for logging events and errors for debugging. Applications also need timestamps to record statistics for benchmarking. DNS needs timestamps for renewing the domain mappings. Browsers need to know the current time to validate the TLS certificates. Distributed applications need synchronized time for coordinating real-world activities such as running airplanes, factories, and hospitals.
We started the post by describing the clock synchronization problem in distributed systems. We examined the differences between atomic and astronomical clocks and the inconsistencies in different time measurement standards. We briefly discussed the definition of the most common standard for timekeeping in computers: UTC and Unix Time.
Towards the end, we looked at two clock synchronization protocols: NTP and TrueTime. We compared their performance. We also understood the trade-off space for keeping the clocks consistent across the network.
Notes
Clock skew cannot be zero even if there is no drift. It is proved that in realistic networks, even if the clocks all run at the same rate as real time and there are no failures since there is some uncertainty in the message delivery time, it is impossible to synchronize the clocks.
If the upstream and downstream latency is the same, then we can calculate the delays as half of the difference between two timestamps (when clients start a request and when it receives a response from the time server).
Note that two monotonic timestamps are not comparable if they come from two different devices.
The cause of the error was
rand.Int63n()function which panics if its argument is negative.This observation is in line with Barbara Liskov's finding that globally synchronized clocks can improve the performance of a distributed system by reducing communication overhead.